논문: NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE

❍ ICLR 2015
ABSTRACT
번역 성능 극대화 하기 위한 single neural network. 주로 인코더-디코더의 구조.
=> source 문장을 고정 길이 벡터(fixed-lenght vector)로 인코딩 후 디코더가 이를 활용해 번역 생성
* 고정 길이 벡터의 사용: 인코더-디코더에 병목 현상 일으켜.
=> 모델이 단어를 예측하는데 도움이 되는 source의 일부를 자유롭게 찾아낼 수 있는 방식 제안.
* 영어 -> 프랑스어로의 번역 작업에서 좋은 성능 달성
모델이 찾아낸 (soft-) alignments 가 저자들의 직관과 일치함 보임
📚 [인코더-디코더 구조에서의 병목 현상]

인코더가 입력 문장의 모든 단어를 순차적으로 받아
마지막에 단어들로부터 얻은 정보 압축해 하나의 벡터로 만들어
= CONTEXT Vector (입력 문장에 대한 문맥적인 정보)
디코더는 해당 벡터를 받아 번역된 단어를 하나씩 순차적으로 출력
앞 단어에 대한 계산이 끝나야 다음 단어의 계산 진행 가능 -> 정보 흐름에 Bottleneck 발생
입력 문장 길이에 상관 없이, 고정된 크기를 가진 context vector에 정보를 압축해야 하므로 전체 성능에서 bottleneck의 원인
✍️
align ≡ attention
annotation ≡ hidden state
1. INTRODUCTION
* 기존의 구문 기반 번역 시스템(Koehn) => Statistical phrase-based translation (STM)
어휘 정렬, 구문 표현, 번역 모델 학습, 디코딩: 여러 단계로 나누어 처리
1. 어휘 정렬: 원본과 대상 문장의 단어 사이의 어휘적 매칭
2. 구문 표현: 문장 구조적 정보 고려한 구문 표현 생성(ex_ 구문 트리, 구문적으로 정렬된 문장 쌍 생성)
3. 번역 모델 학습: 원본과 대상 문장 사이의 구문 표현과 번역의 관련성 학습
4. 디코딩: 새로운 입력 문장 번역 과정, 가능한 번역 후보 생성하고 점수 부여해 최적의 번역 선택
대부분의 neural machine translation model은 인코더-디코더의 구조
=> 긴 문장에서의 성능 떨어진다..
=> jointly trained to maximize the probability of a correct translation given a source sentence.
==> 인코더-디코더 모델에 align과 번역을 함께 학습하는 확장 기법 소개
- 각 단어를 생성할 때, 원문에서 가장 관련 있는 정보가 있는 위치 집합 탐색 (soft-search)
- 해당 위치와 이전에 생성된 모든 대상 단어와 관련된 context 벡터를 기반으로 단어 예측
입력 문장을 순차적으로 탐색해서 현재 생성하려는 부분과 가장 관련있는 영역을 적용시킨다.
최종적으로 encoder에서 생성한 context word 중 관련성이 크다고 판단되는 영역들과,
decoder에서 이미 생성한 결과를 기반으로 다음 단어를 결과로 생성해낸다.
?? 입력 문장 전체를 하나의 고정 길이 벡터로 인코딩하지 않는다.
일련의 벡터로 인코딩 -> 번역 과정에서 하위 집합을 선택. 모든 정보를 고정 길이 벡터로 압축할 필요 없어
긴 문장을 더 잘 처리할 수 있다
☑ align과 번역을 동시에 학습하는 접근 방식 >> 인코더-디코더 방식보다 향상된 성능
_긴 문장에서 두드러짐
2. BACKGROUND: NEURAL MACHINE TRANSLATION
확률 관점 _번역 => 타겟 문장 y의 조건부 확률 최대화 하는 y를 찾는 것.
신경망 모델에서 문자 쌍의 조건부 확률을 최대화 하기 위한 매개변수 모델 학습
2.1 RNN ENCODER–DECODER
align and translate 동시에 학습하는 구조의 기반이 되는 개념 소개
❍ Encoder: 입력 문장 x를 읽어 하나의 벡터 c 로 인코딩

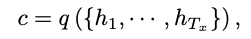
h: hidden stae at time t
c: vector generated from the sequence of the h
f, q: nonlinear function (LSTM)
❍ Decoer:

벡터 c와 이전에 예측된 모든 단어 {y1, ..., yt-1}이 주어지면 다음 단어 yt'을 예측하도록 훈련
y에 대한 확률은 조건부 확률을 기반으로 생성됨
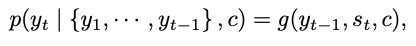
g: nonlinear, potentially multi-layered function
st: hiddent state of RNN
3. LEARNING TO ALIGN AND TRANSLATE
양방향 RNN을 인코더로, 디코더는 번역 생성하는 동안 원본 문장 탐색
3.1 DECODER: GENERAL DESCRIPTION
새로운 모델에서 조건부 확률 정의: ci 가 각각의 yi에 추가된 것 확인
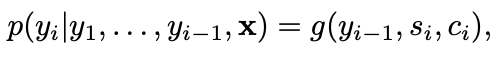

si: RNN hiddent state for time i
ci: context vector _depends on a sequence of annotations (h1, ... , hTx), 전체 input sequence에 대한 정보를 포함
[특히 i번째 단어에 초점]


aij: weight
eij: alignment model, input_j와 output_i의 출력이 얼마나 잘 매칭/일치하는지에 대한 점수
디코더가 yi를 출력하기 전 hidden state s(i-1)은 이전에 예측된 단어들을 포함한다.
이 점수를 기반으로 디코더는 올바른 위치에 해당하는 입력 정보를 찾아내고, 문장 생성 => 번역을 더 정확하게 수행
alignment model "a" : 하나의 feedforward neural network로 구성, 다른 네트워크와 같이 학습
가장 마지막 변수를 고려 X, diredctly computes a soft alignment,
=> 각 디코딩 단계에서 모델이 입력 문장과 출력 문장 사이의 관련 점수를 계산한다
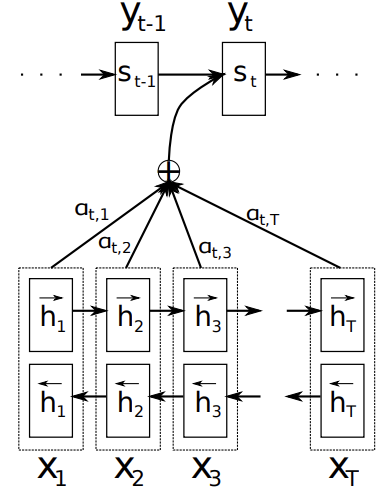
3.2 ENCODER: BIDIRECTIONAL RNN FOR ANNOTATING SEQUENCES
양방향 RNN(BiRNN): 순방향(주어진 순서대로 x1, ..., xT 읽어 hidden state 계산), 역방향 RNN으로 구성
두 RNN의 결과 순방향 h와 역방향 h를 연결해 hj 생성
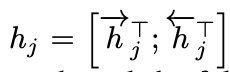
인접한 state의 정보를 더 많이 가지고 있는 RNN의 특성상, hj는 입력 단어 xj의 가까운 위치에 있는 단어의 정보를 더 많이 보유하게 된다.
4. EXPERIMENT SETTINGS
4.1 DATASET
❍ English-French parallel corpus (by ACL WMT ’14)
- 전체 corpus 단어를 348M개로 제한, 크기 축소
- monolingual data는 사용하지 않음
4.2 MODELS
2 types of models
❍ [기존] RNN Encoder–Decoder: 1000개의 hidden unit
❍ [제안] RNNsearch: 1000개의 순방향 + 1000개의 역방향 hidden unit
학습 방법
> 30 단어 문장
> 50 단어 문장
두 모델 모두 multilayer network with single maxout 사용
minibatch stochastic gradient descent(SGD) 알고리즘 (80) + Adadelta 사용
훈련된 모델 -> beam search 사용, 조건부 확률 최대화 하는 번역 찾아
[minibatch stochastic gradient descent]
훈련데이터를 미니 배치로 나누고, 각각에 대해 gradient descent 적용 => 모델의 가중치 업데이트
훈련 시간 줄이고 계산량 감소, 모델 성능 향상
[Adadelta]: AdaGrade 기반의 최적화 알고리즘
Accumulated Squared Gradient/Update
1. 누적 제곱 gradient 계산: 매개변수 갱신을 위해 과거 gradient 제곱 누적.
2. 누적 제곱 업데이트: 이전 업데이트의 제곱 누적
3. 새로운 gardient 계산. 현재 스텝에서 gradient를 계산한다
4. learning rate 조정: 현재 & dlwjs gradient 이용해 학습률 계산, 과거 gradient 들이 얼마나 중요한지에 따라
5. 매개변수 업데이트
=> gradient가 크거나 작은 경우에도 일반적으로 잘 작동한다
[beam search]: 자연어 처리/기계 번역에 사용되는 탐색 알고리즘
모든 시퀀스를 탐색하지 X, 가장 가능성이 높은 시퀀스 찾기 위해 최적화된 탐색 방법: 너비 우선 탐색 + 그리디 알고리즘 결합
1. 시작 단어에 대해 가능한 모든 다음 단어의 조합 계산: 초기 beam 생성
2. 빔 확장: 빔의 각 상태에서 가능한 다음 단어 후보 계산 - 빔의 상태는 이전에 생성된 단어 조합, 이에 대한 다음 단어 예측
3. 빔 정렬: 가능한 다음 단어 후보 중 가능성 가장 높은 빔의 크기만큼 단어 선택 => 다음 단계의 빔 생성
4. 최종 단어 결정: 특정 조건(ex_ 문장 끝 도달) 충족하는 단어 시퀀스 찾을 때까지 확장->정렬 단계 반복
가능한 모든 시퀀스 탐색보다 효율적으로 가능성이 높은 시퀀스를 찾을 수 있다- beam 크기를 늘리면 더 정확한 결과를 얻을 수 있지만 계산 비용 증가
5. RESULTS
5.1 QUANTITATIVE RESULTS

BLEU score를 기반 translation 성능을 평가. RNNsearch 가 모든 경우 더 뛰어난 성능을 제공
기존의 phrase-based translation system(Moses) 와 유사한 성능

본 논문에서 제시하는 모델의 장점 = source sentence를 하나의 고정된 길이의 벡터로 변환하지 않아도 된다
하나의 고정된 길이의 벡터로 변환하는 경우, 문장의 길이가 길어지면 성능이 떨어진다.
=> RNNsearch-30, RNNsearch-50의 경우, source sentence 가 길어져도 어느정도 일관된 성능을 제공ㅇㅇ
RNNsearch-50은 특히 문장이 길이가 계속 길어져도 성능 저하가 없음!
5.2 QUANTITATIVE ANALYSIS
5.2.1 ALIGNMENT
영어-프랑스어 특징적 차이 = 형용사 | 명사의 어순
: 잘 정렬함^^
5.2.2 LONG SENTENCES
: 긴 문장의 경우도 누락 없이 잘 번역^^
+ 수식 why..?
'👩💻 도비는 공부중 > 📋 연구과제(2023.7 ~ )' 카테고리의 다른 글
| [Setup] Window | Anaconda | Pytorch | CUDA | CUDNN (0) | 2023.07.21 |
|---|---|
| SimGNN: A Neural Network Approach to Fast Graph Similarity Computation (0) | 2023.07.21 |
| [세미나] 준비 과정 | 시작이 절반 | 발표는 어려워 | 피드백 (1) | 2023.07.19 |
| Set-to-Sequence Methods in Machine Learning:a Review (0) | 2023.07.14 |
| Pointer Networks (1) | 2023.07.13 |



