[과정 이해하기]
1. Merge
FRT와 Motion data의 시간 동기화 > 병합 > 하나의 보행 데이터 파일 생성
merge_Files_in_Folders(DIR_Src = Dataset/2022_11_10)
┗ create a folder for the merged files
원래 폴더명에 _M을 붙어서 새로운 폴더를 만들어
list of devices = [shadow, hs_server]
2. Labelling
보행 데이터의 정보 이용해 마지막 col 에 'TAG' 부여
label_config > shadowdata | smartinsoldata
3. FeatureSelection
'feature_config_xlsx' 이용해 라벨링된 데이터로부터 특징 재정렬 > 데이터 파일로 저장 > 특징 설정별로 폴더 생성해 데이터 관리
feature_config > class | IMU | SmartInsole | JointEncoder | ShadowMocap
4. Split
병합된 파일 이용해 K-Fold CV 기법 적용해 폴더 구성
5. Learning SW
특징별로 구성된 폴더와 'training_config.xlsx' 파일 이용한 신경망 학습 > 결과 파일 생성
training_config > case | Window size | Window step | Prediction Step | LSTM_Units | Epoch | batch size
training_config 파일 읽어 > Case 파악 > 폴더의 위치를 리스트로 관리
1. data reshape
(time * window size * features) > (time * features * window size) window size = sliding window
• 16 | 32 | 64 | 128 조절
• pathience = 5 : 10 ~ 12 epoch 에서 early stopping
+ shape 변경 이유는 딱히 없음 > 이게 맞을 것 같다
++ Data 수가 적으면 모델이 복잡한게 좋을거에요.. << 데이터가 많으니까 단순한 모델 사용
윈도우 크기가 연산 속도 및 변이 구간에서의 예측 성능에 영향
> 동작과 동작 사이의 변이 구간을 어떻게 레이블링하느냐에 따라 달라져

EX_ 걷는 동작 >> 변이 구간 >> 허리 숙이기
window size 작으면 변이 구간 포착 쉬워 > 잘 예측
window size 크면 다양한 동작들 중 어떤 걸로 예측할지 몰라 성능 오히려 안좋아질 수 있음
2. Data Augment





* 성능 비교: 원본 데이터 | 증폭한 데이터 (window size = 16)
87 >>> 99까지 갑자기 오른다?
* train | test | val dataset split 과정
> test data는 중폭시키면 안될듯
3. model 변경
[original] BidirectionalLSTM
• CNN: ValueError ???
시계열 데이터 > 이미지 처럼 읽어들이기
class CNN:
@staticmethod
def build(n_timesteps, n_features, classes):
input_shape = Input(shape=(n_timesteps, n_features, 1))
model = models.Sequential([
layers.Conv2D(filters=32, kernel_size=(3, 3), activation='relu', input_shape=input_shape),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Conv2D(filters=64, kernel_size=(3, 3), activation='relu'),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(classes, activation='softmax')
])
return model
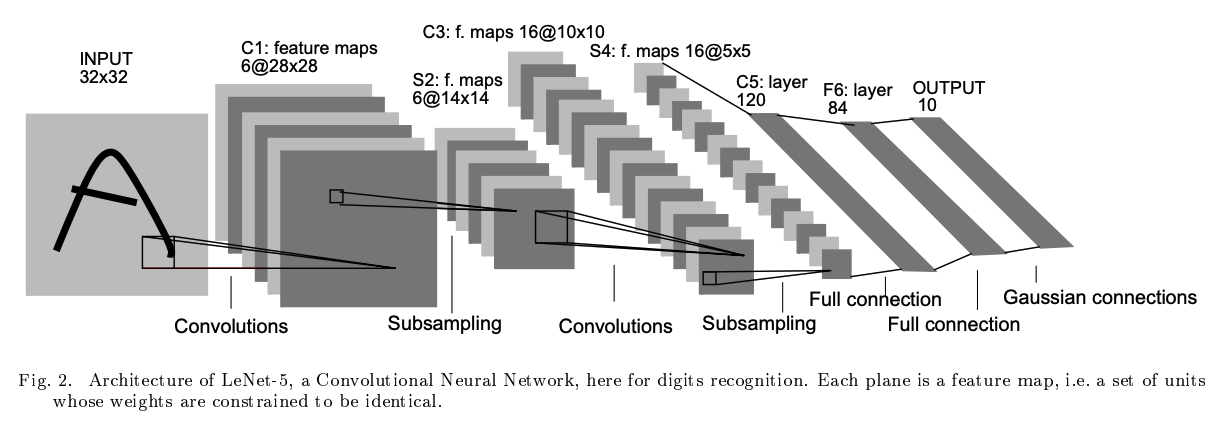
• LeNet5 [paper]
LeNet5나 CNN 이나 사실 비슷..
LeNet 이 CNN의 초기 버전 (상대적 간단하고 작은 모델) > 숫자 인식 같은 작업을 위해 개발된
'👩💻 도비는 공부중 > 💼 하계연구연수생(2023)' 카테고리의 다른 글
| [hdf5] 대용량 데이터 처리 (0) | 2023.08.29 |
|---|---|
| [공유 세미나] 2023 상반기 학회 (0) | 2023.08.18 |
| [미해결] [Unreal] Motion Capture Data | Visualizing with UE5 (0) | 2023.08.18 |
| [Python] configparser (0) | 2023.08.18 |
| [Python] 실행파일(.exe) 만들기 | pyinstaller (0) | 2023.08.11 |


