CVPR - Detecting Everything in the open World: Towards universal object detection

Everything | Open World | Universal
image + text 공간의 alignment > multiple sources & heterogeneous label space image
Open World
└ Unseen classes: Open-vocabulary object detection
└ Various domains: Object detection in the Wild

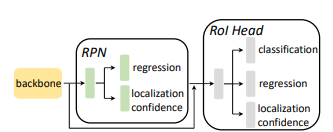


Feature extractor | Domain discriminator | Classifier | + Weight Allocator
automatically fit task-specific weighting functions
ICML 2023 Conference
❍ Expo: Talk Panel: Colossal-AI: Breakthroughs in Efficient AI
┗ 3 layer(Efficient Memory system | 2-dim parallelism system | Large-scale Optimizaion) 딥러닝 모델 학습 효과적 진행 도와줌
❍ Tutorials
┗ Tutorial on Multimodal Machine Learning: Principles, Challenges and Open Questions (link)
┗ How to DP-fy ML: A Practical Tutorial to Machine Learning with Differential Privacy (link)
❍ Fairness/Ethical AI
┗ Learning Fair representations (link)
1. Learning-Rate-Free Learning by D-Adaptation (paper) (github)
- Distance-to-solution의 LB를 가지고, step size 자동 조절 알고리즘 제시
- SGD, AdaGrad and Adam 적용
2. A Watermark for Large Language Models (paper) (github)
- LLM 모델 | 사람의 응답을 구별하기 위한 Watermark 방법론
- 재학습 필요 X
3. Generative Casual Representation Learning for Out-of-Distribution Motion Forecasting (paper) (github)
- 동작 예측 > domain 변화에 강한 예측기 제안

4. Motion Question Answering via Modular Motion Programs (link)
- motion feature 추출, 선후 관계에 대한 학습 > 동작에 대한 Q&A 가능

5. Masked Trajectory Models for Prediction, Representation, and Control (link)
- 강인제어 문제에 MTM(Maksed Trajectory Modeling)

MTM learns versatile networks that can take on different roles or capabilities, by simply choosing appropriate masks at inference time
CVPR - Conditional Generation of Audio from Video via Foley Analogies

Foley = sound effects
"generate a soundtrack for an input silent video from a user-provided conditional audio-visual example"
learn to adapt the exaemplar sound to match the timeing of the visual content of a silentt video

❍ Conditional Foley generation - Transformer
❍ Vector-quantized audio representation - VOGAN
❍ Video input representation
❍ Conditional audio representation: vector quntized embeddings
❍ Combine tokends into a single sequence
❍ Model training
❍ Autoregressive sound prediction
❍ Generating a waveform
❍ Re-ranking based on audio-visual synchronization
'👩💻 도비는 공부중 > 💼 하계연구연수생(2023)' 카테고리의 다른 글
| Time Series Data > Machine Learning (0) | 2023.08.31 |
|---|---|
| [hdf5] 대용량 데이터 처리 (0) | 2023.08.29 |
| [미해결] [Unreal] Motion Capture Data | Visualizing with UE5 (0) | 2023.08.18 |
| [Python] configparser (0) | 2023.08.18 |
| [Python] 실행파일(.exe) 만들기 | pyinstaller (0) | 2023.08.11 |


